Azure API Management (APIM) service is the most complex service/product I have supported so far. The fact that it's a cloud PaaS offering that can be used as a gateway for any form of backend service (hosted on-premise or private cloud) makes it very complex. But then, I was able to be up to speed in little time and overcame all the challenges I came across.
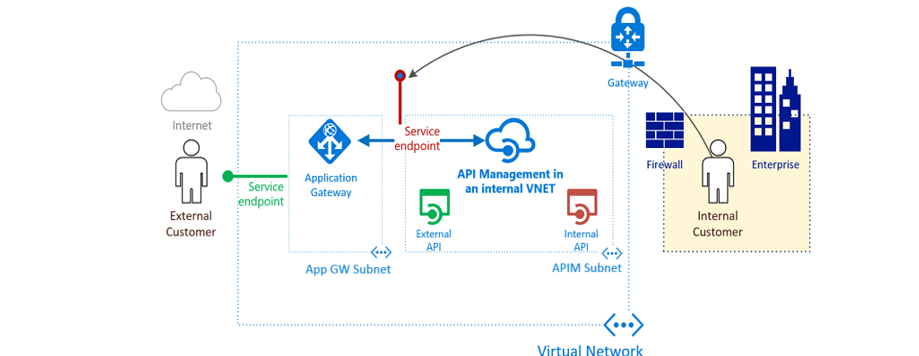
One of the complex features of the service is the ability to deploy it in a virtual network (external or internal). When an APIM is deployed in an internal virtual network, it still needs to be exposed publicly via a layer-7 load balancer (e.g. Azure App Gateway).
Below are some of the strategies I used to handle the complexity of the service:
- Starting from the basics and leaving no stone unturned, I made sure I understood how everything works (in the service) under the hood.
- I always find time to keep learning about the service, even during my off days, using the official documentation by Microsoft.
- I created a personal troubleshooting flowchart that helps in narrowing down the exact issues/components.
- I invested greatly in documentation of issues and resolutions. This also helps in resolving similar/reoccurring issues.
- I built a special and healthy relationship with the product team (SMEs and Software Engineers) that developed the product. We connect at daily triage sessions and post RCA requests on our chat channel.
- More like I was taught, I always try to teach peers and new engineers my new discoveries about the product.
I will be highlighting a few of the issues customer raised support ticket for, the key step taken, and their resolutions.
Issue: APIM admin is unable to publish the APIM service developer portal after moving the APIM service to internal network.
Key Step: After checking the customer's configuration from the backend and I could not find any hint, I collected HAR browser trace from customer while he reproduced the issue.
Cause and Resolution: For APIM services deployed in internal VNet, the service endpoints are not available externally and cannot be reached as such. A layer-7 load balancer(like Azure App Gateway) is required. Admin App Gateway firewall rules (WAF) were blocking calls (from the browser) to management endpoints inside APIM service. I recommended Admin review their firewall rules or put it in detection mode temprarily (instead of prevention mode) and try again. This resolved the customer's issue.
Issue: APIM admin deleted APIM service and couldn’t create another one with same name.
Key Step: I found a documentation on how to purge deleted APIM service and provided same to customer with explanation.
Cause and Resolution: Upon deleting an API Management instance, the service would still exist in a deleted state for the next 48 hours, making it inaccessible to any APIM operations. But the APIM instance in this state can be listed, recovered, or purged (permanently deleted). Hence the reason why the instance name is not available for reuse yet. The customer had two options - to wait till after 48 hours when the APIM service would be automatically hard deleted (unrecoverable) or use the Purge operation to permanently delete his API Management instance from Azure instantly. Why wait when he had a lot to get done? He purged the service and was able to recreate it with same name instantly.
**Issue: ** Customer's connection was getting reset when base64 encoded & ZPL2 data exist in response.
Key Step: This was one of the toughesst cases I had to work on. I went on remote session with cx while he reproduced the issue. I thought the issue might be between APIM and customer's backend service. I then gave csutomer the REST API call to reconnect (reset) backend connection(s). This got the issue resolved temporarily only for the customer to re-open the ticket after like 5 weeks. This time, I noticed the response was making it back to the APIM before the connections get reset. Hence, the issue was between the APIM and the client. we traced the issue to App Gateway but that was not the cause. After ruling out the App Gateway, I asked if customer had any sort of firewall device in their environment. He confirmed that they have an on-premise firewall.
Cause and Resolution: This made us to start checking the logs till we saw where the firewall was blocking requests from APIM service. The customer then started troubleshooting the issue with his internal network team and gave permission to close the ticket.
Issue: Customer was getting the error "400 Bad Request - Invalid URL"
Key Step: I observed that the gateway URL from the log i quite longer than 260 characters which is the maximum (default) length of URL path segment supported by APIM.
Cause and Resolution: The maximum length of URL path segment was exceeded. To increase this limit, requests has to be made to the APIM product team. I therefore made the request to increase the limit for the customer. Wihin 24 hours, this request was granted and the customer was happy.
Issue: APIM admin could not make APIM forward request to itself using the request URL.
Key Step: After series of research and troubleshooting, I realized the cause of the issue is actually the limitation of internal load balancer used in APIM services.
Cause and Resolution: For APIM service in internal VNet mode, the load balancer of gateway (proxy) endpoint is in the same subnet where APIM backend instances are deployed in. When one of the participant backend VMs is trying to access the internal Load Balancer frontend, failures can occur when the flow is mapped to the originating VM (same VM). This scenario is not supported by the internal load balancer.
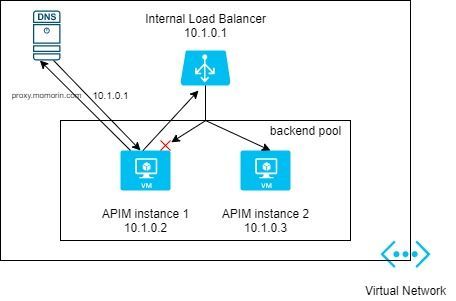
Internal Load Balancer (image from: Microsoft Tech Community)
This issue consistently occurs in Developer Sku as it has only one VM instance as the APIM backend pool. Because Premier Sku has at least two VMs in the subnet, issue may intermittently happen (traffic from instance 1 to instance2 will succeed, traffic from instance 1 back to instance 1 will fail).
The solution that worked was changing the URL of the API in the policy to the form "https://127.0.0.1/.../..." or "https://localhost/.../..." for mapping to loopback interface on the originating (same) VM.